70. [System Design] 10. Partitioning: Rebalancing Partitions and Request Routing
Bài này sẽ nói đến 2 chương còn lại của phần Partitioning: Rebalancing partitions và Request Routing
Rebalancing Partitions
Theo thời gian, có một số thứ thay đổi với database:
- The query throughput increase, do đó cần phải scale database. Có thể bằng cách thêm RAM, CPU
- Datasize increase, cần phải thêm RAM, Disk
- Machine fail
Những sự thay đổi này đòi hỏi data và request di chuyển từ node này sang node khác. Quá trình này gọi là rebalancing.
Bất kể phương pháp parition nào được sử dụng, rebalancing thường đòi hỏi đáp ứng một số yêu cầu tối thiểu sau:
- Sau khi rebalancing, the load (data storage, read and write request) phải được phân phối đều giữa các node
- Trong khi rebalancing đang xảy ra, database phải tiếp tục hoạt động bình thường, tiếp tục chấp nhận read và write request
- Lượng data cần di chuyển giữa các node là tối thiểu. Nó làm cho việc rebalancing nhanh hơn, giảm tải cho network và disk I/O
Có nhiều cách để assign parition vào node. Ta sẽ tham khảo một số cách phổ biến
Hash mod n (ko nên dùng)
Khi thực hiện parition bởi hash key, sẽ tốt hơn khi chia hash key thành nhiều range khác nhau, và gán ranges tương ứng với parition. Ví dụ, partition 0 chứa 0 <= hash(key) < b0, parition 1 chứa b0 <= hash(key) < b1, …
Có thể bạn sẽ hỏi tại sao không sử dụng mod (% operator trong Java)? Giả sử ta có 10 node, xác định key thuộc về node nào bằng cách: node = hash(key) % 10.
Vấn đề chính với phương pháp này, là khi số lượng node thay đổi (có thể là thêm hoặc giảm), thì hầu hết dữ liệu sẽ phải di chuyển từ node này sang node khác. Ví dụ, nếu hash(key) = 123456. Nếu ban đầu ta có 10 nodes, ta có 123456 % 10 = 6 ==> assign vào node 6. Nếu ta tăng node lên 11, ta có 123456 % 11 = 3 ==> assign vào node 3. Nếu ta có 12 node, thì sẽ assign vào node 0 (123456 % 12 = 0).
Do đó, phương pháp “hash % n” rất tốn kém.
Fixed number of partitions
Để xử lý vấn đề này, có 1 phương pháp đơn giản, ta sẽ gia tăng số lượng parition nhiều hơn so với số lượng node, khi đó, 1 node có thể có nhiều parition. Nếu ta có 10 nodes, thì có thể có 1000 parition.
Khi số lượng node thay đổi, ta chỉ cần di chuyển một số parition sao cho dữ liệu được phần phối đều. Xem hình 6-6. Ở hình này, khi thêm node 4, p4 ở node 0, p9 ở node 1, p14 ở node 2, p19 ở node 3 sẽ di chuyển sang node 4.
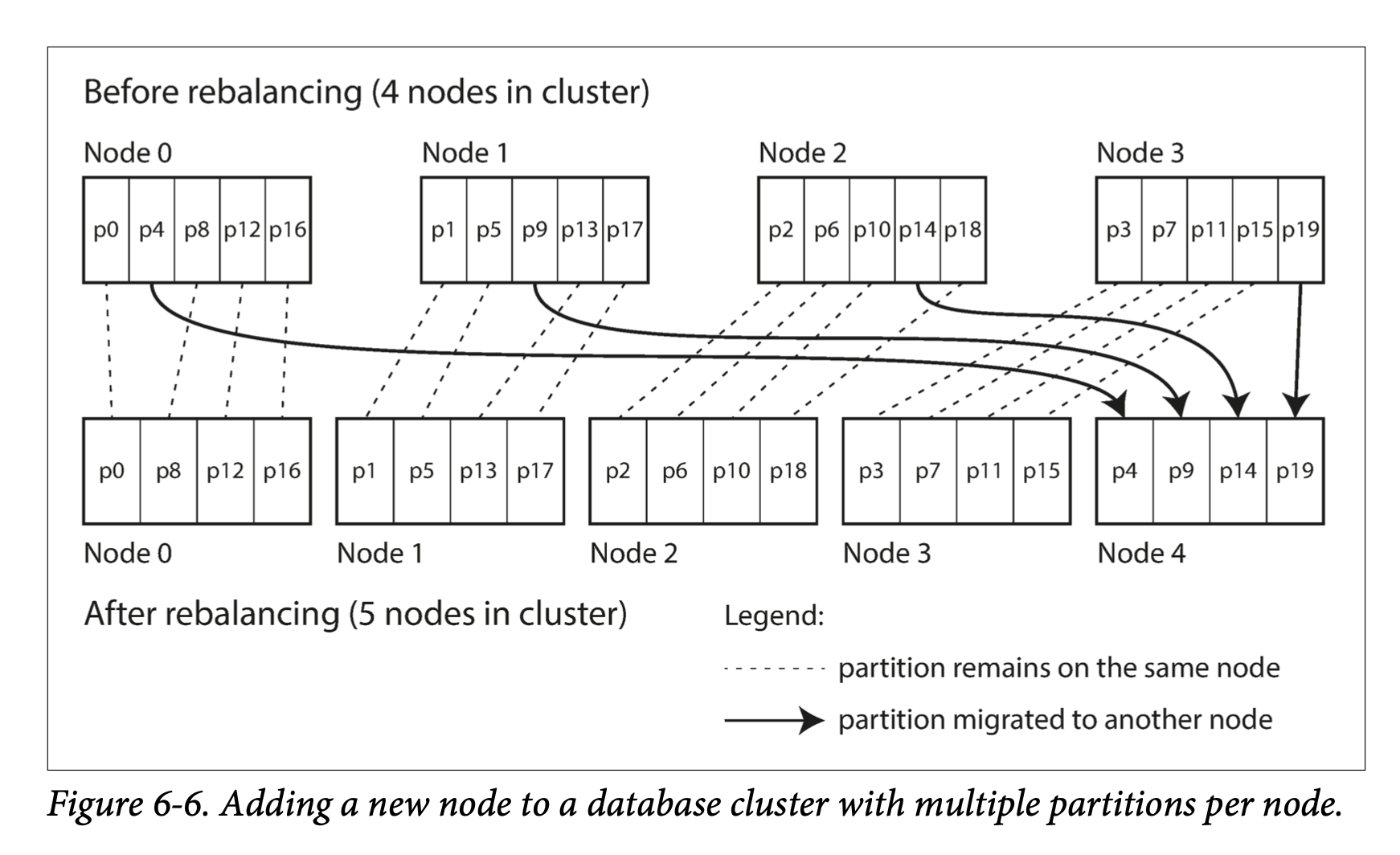
Với phương pháp này, số lượng parition không đổi. Key assign vào parition không đổi. Cái thay đổi chính là việc assign partition vào node. Việc thay đổi này không xảy ra ngay lập tức - bởi vì cần thời gian để transfer một lượng lớn data sang node khác. Trong quá trình chuyển đổi, read/write vẫn được diễn ra trên parition ở node cũ.
Chọn số lượng partition là một việc khó. Với phương pháp này, số lượng partition được chọn từ lúc ban đầu và không thay đổi theo thời gian. Tuy nhiên, theo thời gian, data sẽ gia tăng và làm cho kích thước parition bị phình, ảnh hưởng tới performance. Nhưng nếu chọn số lượng parition quá nhiều, sẽ gây những overhead không cần thiết, cũng ảnh hưởng tới performance. Ngoài ra, một số hệ điều hành cũng giới hạn số lượng file tối đa có thể chứa trong 1 folder (https://stackoverflow.com/questions/466521/how-many-files-can-i-put-in-a-directory)
Dynamic Partition
Một số database như HBase sử dụng phương pháp key range-partitioned với dynamic partition. Khi kích thước của parition vượt quá một ngưỡng nào đó (với HBase là 10GB) thì parition này sẽ tự động chia tách thành 2 partition. Nếu có nhiều dữ liệu bị delete và size nhỏ hơn kích thước nào đó, nó sẽ merged partition với nhau.
Điểm lợi của phương pháp này là số lượng parition sẽ thay đổi dựa theo kích thước của dữ liệu.
Dynamic partition không những phù hợp với key range-partitioned data, mà cũng phù hợp với hash-partitioned data. MongoDB hỗ trợ cả key-range và hash paritioning.
Phương pháp dynamic partitioning, số lượng partition tỉ lệ với kích thước của dataset. Việc split và merge partion giữ cho size của partition không quá lớn cũng không quá nhỏ.
Partitioning proportionally to nodes
(Partition tỉ lệ thuật với node)
Cassandra sử dụng 1 phương pháp khác, làm cho số lượng partition tỉ lệ với số lượng node. Có một số đặc tính như sau:
- Số lượng parition/node là cố định
- Nếu số lượng node không thay đổi, size của parition sẽ tăng nếu dataset size tăng
- Khi gia tăng số lượng node, partition size sẽ giảm xuống. Database sẽ chọn ngẫu nhiên 1 số lượng parition, chia tách thành những parition mới và di chuyển một nửa parition mới ngày sang node mới. Đôi khi, việc này cũng gây ra unfair split. Cassandra 3.0 đề xuất thuật toán để tránh việc unfair split này
Operations: Automatic or Manual Rebalancing
Fully Automatic thì thuận tiện những sẽ có những hành vi không đoán trước được. Hơn nữa, việc rebalancing yêu cầu data di chuyển nhiều giữa các node nên nếu không cẩn thận, sẽ gây vị quá tải network.
Nguy hiểm hơn, nếu automatic rebalancing kết hợp với automatic fail detection. Giả sử nếu mạng bị nghẽn hoặc 1 node bị overhead dẫn đến node phản hồi chậm/rất chậm. Những node khác sẽ nghĩ overhead node đã dead và sẽ di chuyển load sang những node khác. Nó làm cho những node khác có thể bị overhead và gây ra phản ứng dây chuyền.
Do đó, sẽ tốt hơn nếu con người/chúng ta kiểm soát việc rebalancing này, kết hợp giữa manual và automation
Request Routing
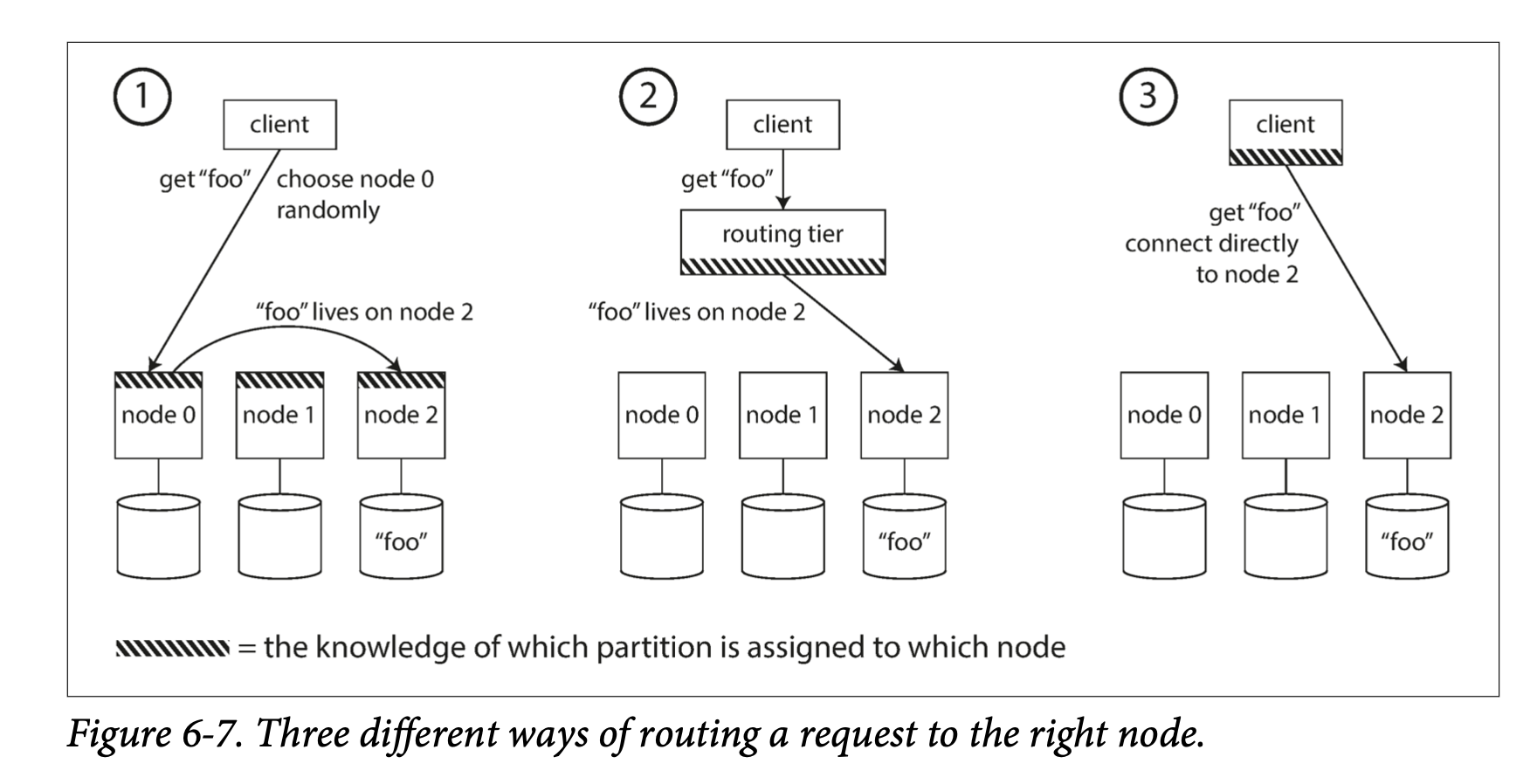
Tới giờ, data được chia thành nhiều parition, nằm ở nhiều node khác nhau. Làm sao khi query, ta xác được được node và partition chứa key đó?
Ở high level, ta có thể có một số cách sau:
- Cho phép client connect tới bất kỳ node nào. Nếu node đó chứa data thì return ngay. Nếu không, node sẽ forward request tới node thích hợp, nhận phản hồi và trả phản hồi này về cho client
- Gửi tất cả request tới routing layer. Routing layer này sẽ xác định route request tới node thích hợp, nó hoạt động như 1 load balancer.
- Cách này yêu cầu client phải biết key thuộc về node nào và request trực tiếp tới node này.
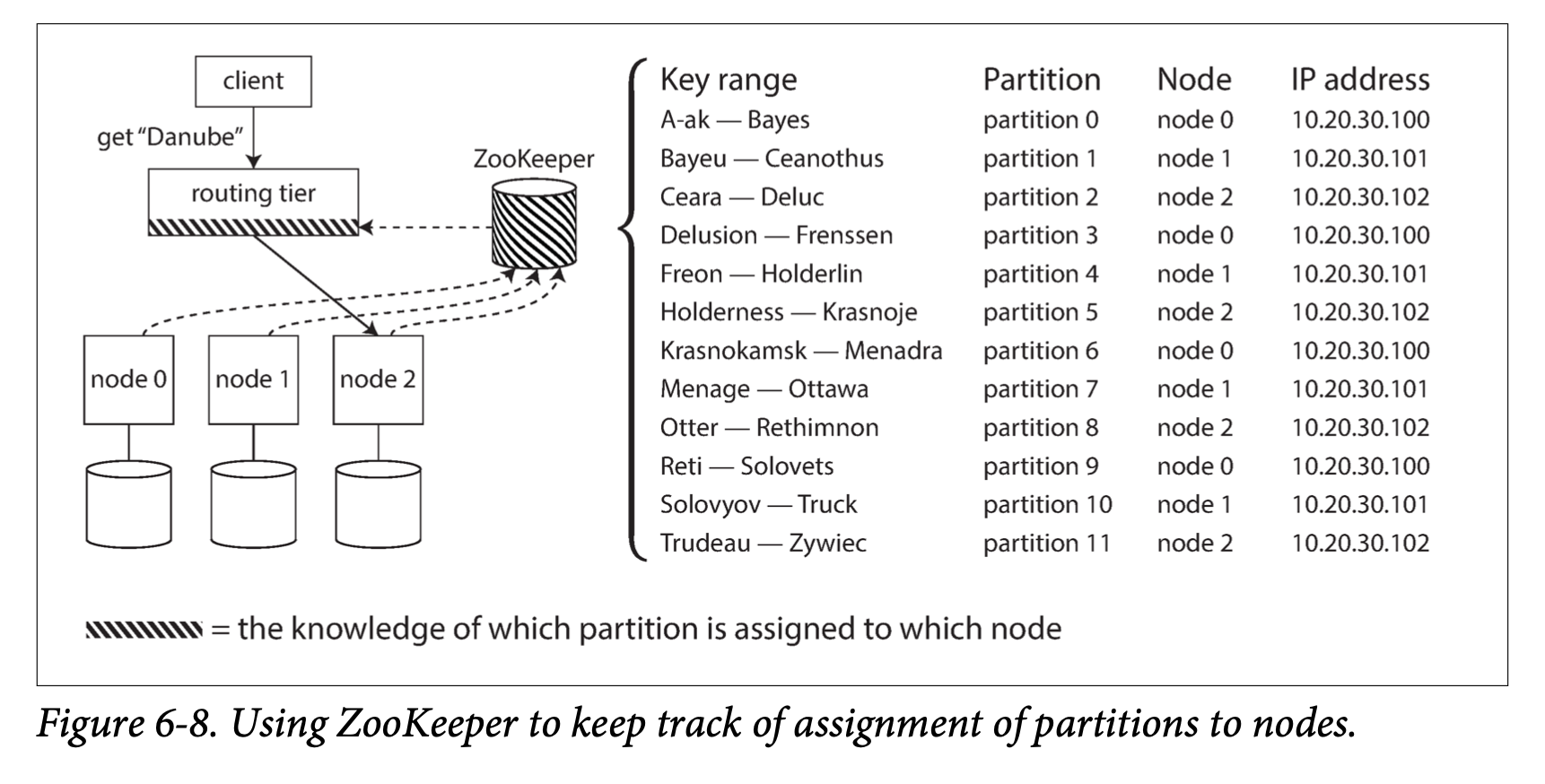
Một số distributed data system dựa vào coordinate service bên thứ 3 như ZooKeeper. ZooKeepr sẽ duy trì (maintain) mapping giữa node và partition. Routing layer sẽ sử dụng thông tin này. Khi có bất kỳ thay đổi nào về parition, node, mapping … ZooKeeper sẽ gửi thông báo với Routing Layer để nó có thông tin mapping mới nhất
Referenes: