69. [System Design] 09. Partitioning: Partition of Primary Key and Secondary Key
Ở chương trước chúng ta nói đến replication - có nhiều bản copy cho cùng 1 data trên nhiều node khác nhau. Tuy nhiên, với dữ liệu lớn (big data - ko thể chứa toàn bộ trong 1 node) hoặc ứng dụng cần very high throughput, như thế là chưa đủ. Partitioning là phương pháp chia nhỏ data thành nhiều phần/parition khác nhau.
Note: Parition là thuật ngữ chung chung. Với mỗi ứng dụng, sẽ có những thuật ngữ riêng, mang cùng ý nghĩa. Với MongoDB, Elasticsearch là shard, BigTable là tablet, Cassandra là vnode, …
Thông thường, parition định nghĩa rằng 1 phần của data (a piece of data như record, document) thuộc về 1 node cụ thể. Nói rõ hơn, nếu record A thuộc về parition 1, thì nó không thể thuộc về bất kỳ parition nào khác. Ta có thể xem mỗi partition là 1 database nhỏ, mặc dù database system có thể hỗ trợ những operation cần kết hợp nhiều partition (ví dụ như join)
Lý do chính cần parition là scalability. Parition thường đi chung với replication. 1 parition được replicate trên nhiều node. Và 1 node có thể có nhiều parition. Replication chia lượng tải bằng cách tạo ra nhiều bản copy, do đó client sẽ query trên nhiều node. Parition chia lượng tải lần 2 bằng cách chia nhỏ data thành nhiều parition, lúc này ta có thể tăng số node cần dùng lên, dẫn đến lượng tải tiếp tục được chia ra
Paritioning of Key-Value data
Khi ta có dữ liệu lớn và quyết định chia nó thành nhiều phần nhỏ, làm sao để xác định vị trí của từng record?
Mục đích chính là chia đều lượng data/tải tới nhiều node khác nhau. Theo lý thuyết, nếu thêm 10 node, có thể chịu tải x10 nếu data được chia đều cho các node. Nếu chia không đều, một vài parition sẽ có data hoặc queries nhiều hơn các node khác. Hiện tượng này gọi là skewed. Và nó làm cho việc chia parition không hiệu quả. Trong trường hợp cực đoan, nếu hầu hết data hoặc query đều tập trung vào 1 node, và 9 node còn lại ở trạng thái idle, thì việc partition thất bại. Trường hợp này gọi là hot spot
Một cách đơn giản để tránh hot spot problem là gán record vào các node randomly. Data sẽ được phân phối đều tới các node nhưng nó có 1 điểm bất lợi rất lớn, khi cần query, ta không biết record đang ở node nào, vì thế cần phải query tới tất cả record để kiểm tra.
Ta có thể làm tốt hơn randomly. Giả sử ta có 1 key-value model và có primary key
Paritioning by key range
Ta có thể dùng key range để parition dữ liệu. Mỗi parition sẽ được assign 1 continuous range (from min to max). Nếu bạn biết key range của parition, thì có thể dễ dàng xác định key cần query thuộc parition nào. Range key không cần phải có size bằng nhau, bởi có thể dữ liệu tập trung vào 1 vài range hơn là những range khác. Ví dụ, tên sách có thể tập trung nhiều ở ký từ A - D, ta có thể coi nó là 1 range. Ký từ từ Q - Z cũng có thể coi là 1 range. Vậy nên, key range boundary phụ thuộc vào đặc điểm của data
Trong mỗi parition, key có thể được sorted. Điều này có lợi khi cần read, cũng như khi cần scan dữ liệu trong 1 range nào đó. Ngoài ra, key không nhất biết phải là số, mà có thể là dạng concatenated key, kết hợp bởi nhiều field với nhau. Ví dụ 20241201_key, …
Tuy nhiên, downside là phương pháp này có thể dẫn tới hot spot. Nếu parition được chia theo ngày tháng, nếu có sự kiện gì xảy ra, thì write/read request sẽ chỉ tập trung vào 1 partion, nhưng parition khác ở trạng thái idle
Để tránh trường hợp này, ta có thể thêm prefix sensor/server name trước timestamp (vd: server120241201…), lúc này key trong timestamp sẽ được tách trên nhiều censor/server
Partitioning by Hash of Key
Vì lý do skewed và hot spot, nhiều distributed storage sử dụng hash để parition key. Một hàm hash tốt sẽ làm cho skewed data được phân phối đồng đều. Hash function không cần bảo mật, chỉ cần data phân phối đồng đều là đủ. Consistent hashing là phương pháp thường được sử dụng ở các distributed system như CDN
Tuy nhiên, khi sử dụng hash key, ta bị mất đi 1 đặc trưng của key-range: khả năng query theo range. Với hash key, 2 key gần nhau có thể nằm ở 2 partion khác nhau, vì giá trị hash khác nhau. Lúc này, ta phải query ở nhiều partition khác nhau.
Cassandra tìm cách thoả hiệp (compromise) giữa 2 phương pháp này. Cassandra khai báo compound primary key, gồm nhiều column. Giả sử key gồm nhiều phần A_B_C,…. Chỉ phần đầu tiên (phần A) được hash để xác định partition, nhưng những phần khác (B_C,..) sẽ được dùng làm concatenated index for sorting data. Do đó, query không thể search range value cho first column, nhưng nếu ta cố định first column, ta có thể thực hiện efficient range scan trên những column còn lại.
Skewed Workloads and Relieving Hot spot
Như đã thảo luận, hash key có thể giảm hot spot. Tuy nhiên, ta không thể tránh nó hoàn toàn. Trong trường hợp extreme, all read and write cùng 1 key, do đó tất cả request sẽ trỏ vào 1 partition.
Với những trường hợp hot key, 1 kỹ thuật đơn giản là add prefix hoặc suffix cho key. Nếu chỉ thêm 2 số thì ta sẽ có thêm 100 keys, cho phép nó được phân phối giữa các parition khác nhau. Tuy nhiên, phương pháp này yêu cầu manual work, do đó chỉ phù hợp với một lượng key nhỏ mà thôi.
Partitioning and Secondary index
Thông thường, secondary index không sử dụng để xác định record (như primary index), mà thường dùng để search 1 giá trị nào đó. Ví dụ search by Name, car, … Vấn đề với secondary index là nó không “map closely” với partition.
Partitioning Secondary Indexes by Document
Giả sử ta có 1 website bán xe, mỗi xe có 1 unique ID - gọi là DocumentId. Ta có thể partition bằng DocumentId. Document 0 - 499 ở partition 0, Document 500-999 ở parition 1, …
Nếu ta muốn search xe bằng color và make, ta có thể tạo secondary index bằng color và make. Index trên color có dạng color:red, color:blue ,…
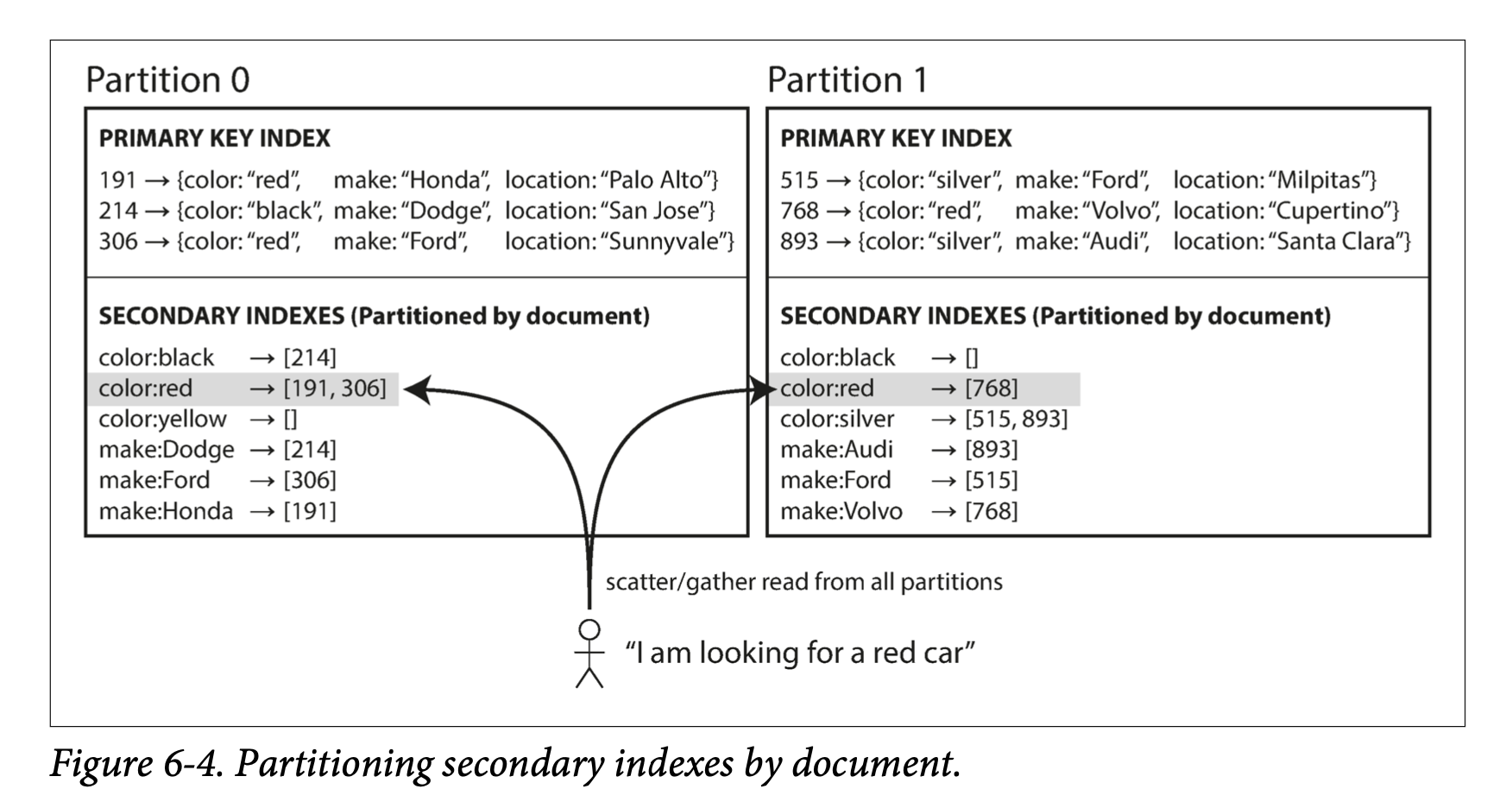
Với phương pháp index by document, mỗi partition sẽ duy trì secondary index riêng, chỉ bao gồm những document trong partition đó. Nó không quan tâm đến data lưu trữ ở những partition khác. Bất cứ khi nào cần write tới database (write, update, delete), ta chỉ làm việc với parition chứa documentId đó. Với nguyên nhân này, document-partitioned index còn được gọi là local index.
Khi làm việc với document-partitioned index, cần lưu ý rằng, không có ràng buộc toàn bộ car có cùng color hoặc make phải nằm gọn trong 1 parition. Như hình 6-4, red car có thể xuất hiện ở partition 0 và partition 1. Do đó, nếu ta muốn query for red cars, ta cần gửi query tới tất cả partition, và sau đó combine kết quả và trả về. Điều này làm cho việc đọc secondary index is quite expsensive. Nó thường đc dùng rộng rãi ở Cassandra, Elasticsearch. Hầu hết các database vendor khuyến nghị thiết kế partition sao cho secondary index chứa trong 1 partition.
Partitioning Secondary Indexes by Term
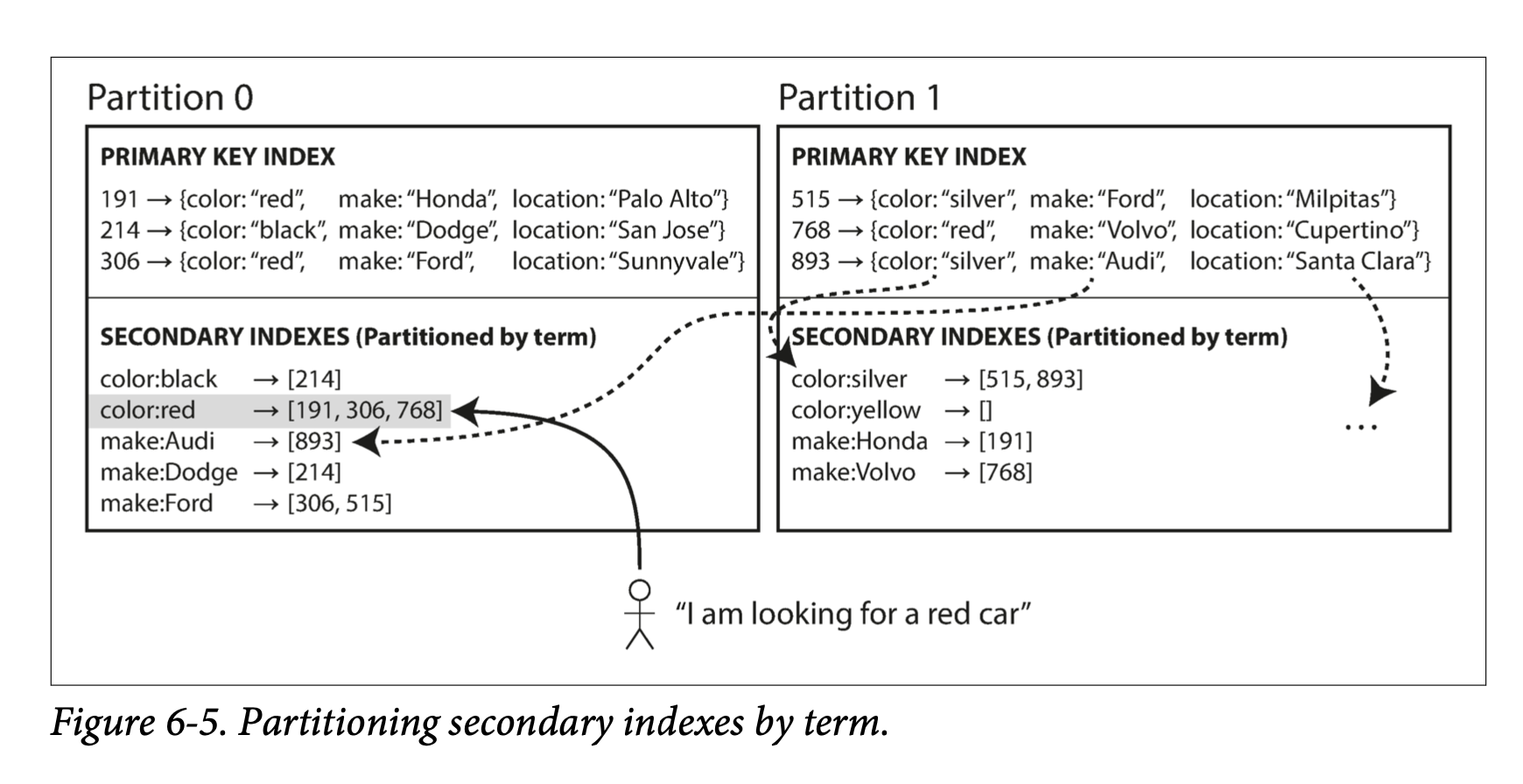
Thay vì mỗi parition có secondary index riêng của nó (local index), ta có thể xây dựng global index bao phủ toàn bộ data trên tất cả partition. Ta cũng không thể lưu index trên 1 node, vì gây ra bottleneck. Global index cũng phải được partition, nhưng cách parition sẽ khác so với primary index
Hình 6-5 mô tả cách tổ chức global index. color:red sẽ chứa index của car với color=red trên tất cả partition. Nhưng index color được partition theo dạng: color từ a-r được chứa ở parition 0, và color từ s - z được chứa trong partition 1. Chúng ta gọi phương pháp này là term-partitioned
So với document-partitioned index, term-partitioned index lợi hơn cho việc read: Client chỉ gần gọi đến partition chứa term cần query, mà không cần phải quét toàn bộ partition. Tuy nhiên, write thì phức tạp và expensive. Với 1 thao tác write, có thể ảnh hưởng tới nhiều index, ở nhiều parition khác nhau. Do đó, trong thực tế, việc update index thường được làm theo dạng async.
Đại diện của phương pháp global index là DynamoDB.
Referenes: