68. [System Design] 08. Replication: phương pháp Masterless
Với 2 phương pháp trước đây, single leader và multi-leader, dựa trên ý tưởng rằng write request sẽ được gửi tới leader node và database sẽ làm nhiệm vụ copy/replicate data tới những node khác.
Một vài database dùng phương pháp khác, loại bỏ khái niệm leader và cho phép write trực tiếp lên bất kỳ replica nào. Ý tưởng này gọi là leaderless hoặc còn được gọi là Dynamo style. Amazon Dynamo, Cassandra, Riak, Voldermort sử dụng ý tưởng này.
Writing to the Database when a node is down
Khi 1 replica bị down, ta sẽ có khái niệm failover với single leader and multi leader approach. Tuy nhiên, với leaderless, ta không có khái niệm này.
Giả sử ta có 3 replica và 1 trong số đó bị down. Giả sử với write request, chỉ cần nhận 2 ok response thì write được xem là thành công. Trong trường hợp này, ta sẽ làm ngơ việc 1 node bị down và chấp nhận write request là thành công nếu nhận được 2 ok response từ 2 node còn lại.
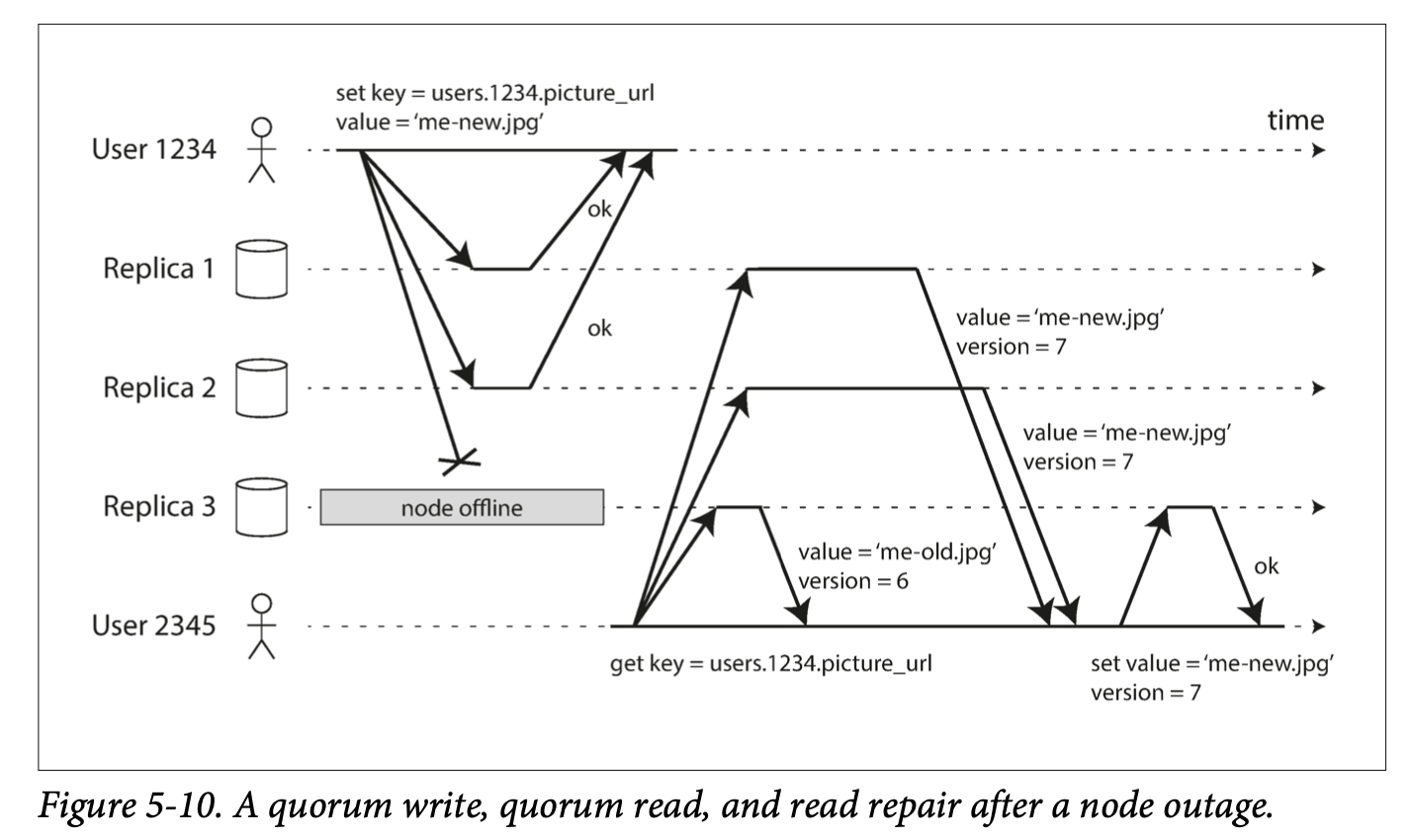
Giả sử khi node bị down hoạt động trở lại, node sẽ bị thiếu những write request khi nó offline. Và nếu client đọc phải những node này, sẽ trả về dữ liệu bị cũ (hay gọi là stale/outdated data).
Để giả quyết vấn đề này, khi đọc, client sẽ đồng thời gửi nhiều read requests tới nhiều node khác nhau. Chúng có thể lấy được dữ liệu up-to-date và stale data. Khi này, có thể dùng version number để xác định giá trị nào mới hơn.
Read repair and anti-entropy
The replication schema đảm bảo rằng, cuối cùng thì data sẽ được copy tới tất cả các replica. Sau khi 1 node từ trạng thái unavailable hoạt động trở lại, làm sao để nó catch-up (cập nhật) ?
Với Dynamo-style datastores, có 2 cơ chế thường được sử dụng:
- Read repair: khi client read đồng thời từ nhiều node, nó có thể phát hiện stale data. Như hình 5-10, user 2345 lấy data version 6 từ replica 3 và version 7 từ replica 1 và 2. Client thấy rằng replica 3 có stale data và sẽ write giá trị mới vào replica này. Phương pháp này hoạt động tốt cho những giá trị được read thường xuyên
- Anti-entropy process: một vài datastores có 1 background process. Nó sẽ luôn tìm kiếm sự khác biệt giữa các replicas và copy những data bị thiếu từ replica này sang replica khác. Không giống với replication log trong trường hợp leader-based replicationr, anti-entropy process không copy writes theo bất kỳ thứ tự cụ thể nào (??? chưa hiểu), và sẽ có significant delay trước khi data được copy
Một vài datastore không có anti-antropy process, nên với những dữ liệu hiếm khi được đọc, có thể có sự mất mát nếu lỗi xảy ra, bởi vì read repair chỉ được thực thi khi data được đọc bởi ứng dụng
Quorums for reading and writing
Nếu ta có n replicas, mỗi write request phải được confirm bởi w node để được xem là thành công, và với read query, ta sẽ query ít nhất r node (Trong ví dụ ở hình 5.10, n = 3, w = 2, r = 2)
Nếu w + r > n, ta có thể mong đợi đọc được up-to-date value khi reading, bởi vì ít nhất 1 trong r node mà chúng ta đọc sẽ có giá trị mới nhất.
Read và write tuân theo quy tắc r và w được gọi là quorum reads and writes.
Với Dynamo-style database, parameter n, w, r sẽ được config. n thường được lựa chọn làm số lẻ (ví dụ 3 hoặc 5), và w = r = (n+1)/2. Tuy nhiên, tuỳ thuộc vào ứng dụng mà ta config riêng. Ví dụ, nếu workload với ít write và nhiều read, có thể setting w = n và r = 1. Điều này làm cho read nhanh hơn, nhưng bất lợi là nếu 1 node fail gây ra tất cả write data đều fail.
- Nếu w < n, ta có thể tiếp tục write nếu 1 node fail/unavailable
- Nếu r < n, ta có thể tiếp tục read nếu 1 node fail/unavailable
- Thông thường, read và write sẽ luôn luôn được gửi một cách sóng song tới tất cả n replica.
Limitations of Quorum Consistency
Nếu ta có n replicas, và chọn w, r sao cho w + r > n, ta có thể mong đợi rằng data trả về sẽ là data mới nhất.
Nếu w + r <= n, có khả năng ta sẽ đọc phải stale data, bởi vì nhiều khả năng sẽ đọc phải node không chứa dữ liệu mới nhất. Tuy nhiên, config này cho phép low latency và higher availability.
Tuy nhiên, kể cả khi w + r > n, vẫn có những edge case (trường hợp đặc biệt), stale data được trả về.
- Sloppy quorum được dùng, khi w writes được ghi vào những node khác với những node được đọc, do đó, không gì đảm bảo việc overlap giữa r nodes và w nodes. Sẽ nói rõ hơn ở phần sau
- Nếu có 2 write xảy ra đồng thời, ta sẽ ko biết request nào xảy ra trước.
- Nếu 1 write xảy ra đồng thời với 1 read, write request chỉ “reflected, xảy ra” ở một số replicas. Trong trường hợp đó, không thể xác định read sẽ trả về old hay new value
- Nếu 1 write thành công ở 1 vài replicas nhưng thất bại ở những replicas khác, và về tổng thể, write request thành công nhỏ hơn w, ta không thể rolled back trên những replica mà nó thành công. Điều đó có nghĩa là nếu write request fail, những read sau đó có thể hoặc không thể trả về giá trị từ write. Theo tôi hiểu, nếu read đọc phải replicas mà ghi thành công, thì trả về giá trị. Nếu đọc phải node mà write fail, thì không trả về giá trị.
- Giả sử 1 node chứa dữ liệu mới ghi bị fail (shutdown), nhưng chưa kịp backup dữ liệu mới này, thì khi phục hồi dữ liệu, sẽ phục hồi dữ liệu cũ (bị thiếu những dữ liệu chưa kịp backup). Và khi đó, số lượng replicas cho new value sẽ nhỏ hơn w, phá vỡ quorum condition
- Ngay cả khi mọi thứ đều hoạt động tốt, có vài edge cases có thể gặp phải do timing gây ra. Xem ở phần “Linearizability and quorums”, trang 334
Mặc dù quorum xem như sự đảm bảo rằng read sẽ trả về dữ liệu mới nhất, nhưng trong thực thế, không có đơn giản như vậy.
Sloppy Quorums and Hinted Handoff
Sloppy quorum: write and read vẫn yêu cầu w và r phản hồi thành công, nhưng chúng có thể bao gồm những node không phải là n “home” nodes. Cụ thể, nếu 1 node trong n node bị fail, ta có thể write tới 1 node khác ngoài n node để đảm bảo số luọng w. Tuy nhiên, khi đọc, ta chỉ đọc từ n “home” node, nên sẽ có khả năng trả về stale data. Sloppy quorum hữu ích trong việc tăng write availability nhưng nó không phải là quorum theo nghĩa truyền thống. Nó chỉ đảm bảo durability
Khi network interruption/fail node được sửa, tất cả write request tới temporarily node (đại diện của node có vấn đề) sẽ được gửi về “home” node. Điều này gọi là hinted handoff
Sloppy quorums là tuỳ chọn. Cassandra disable tính năng này với config mặc định
Detecting Concurrent writes
Dynamo-style database cho phép nhiều client write đồng thời trên cùng 1 key, nghĩa là conflict có thể xảy ra. Conflict có thể xử lý ở read repair hoặc hinted handoff
Vấn đề là những event đến các node với các thứ tự khác nhau. Ví dụ hình 5-12 mô tả 2 clients, A và B, ghi đồng thời key X vào 3 node
- Node 1: nhận write từ A, và ko bao giờ nhận write từ B vì network problem
- Node 2: Đầu tiên, nhận phản hồi write từ A, sau đó write tiếp vào B (chưa biết có nhận được phản hồi hay không)
- Node 3: Đầu tiên, nhận phản hồi write từ B, sau đó write vào A (chưa biết có nhận được phản hồi hay không)
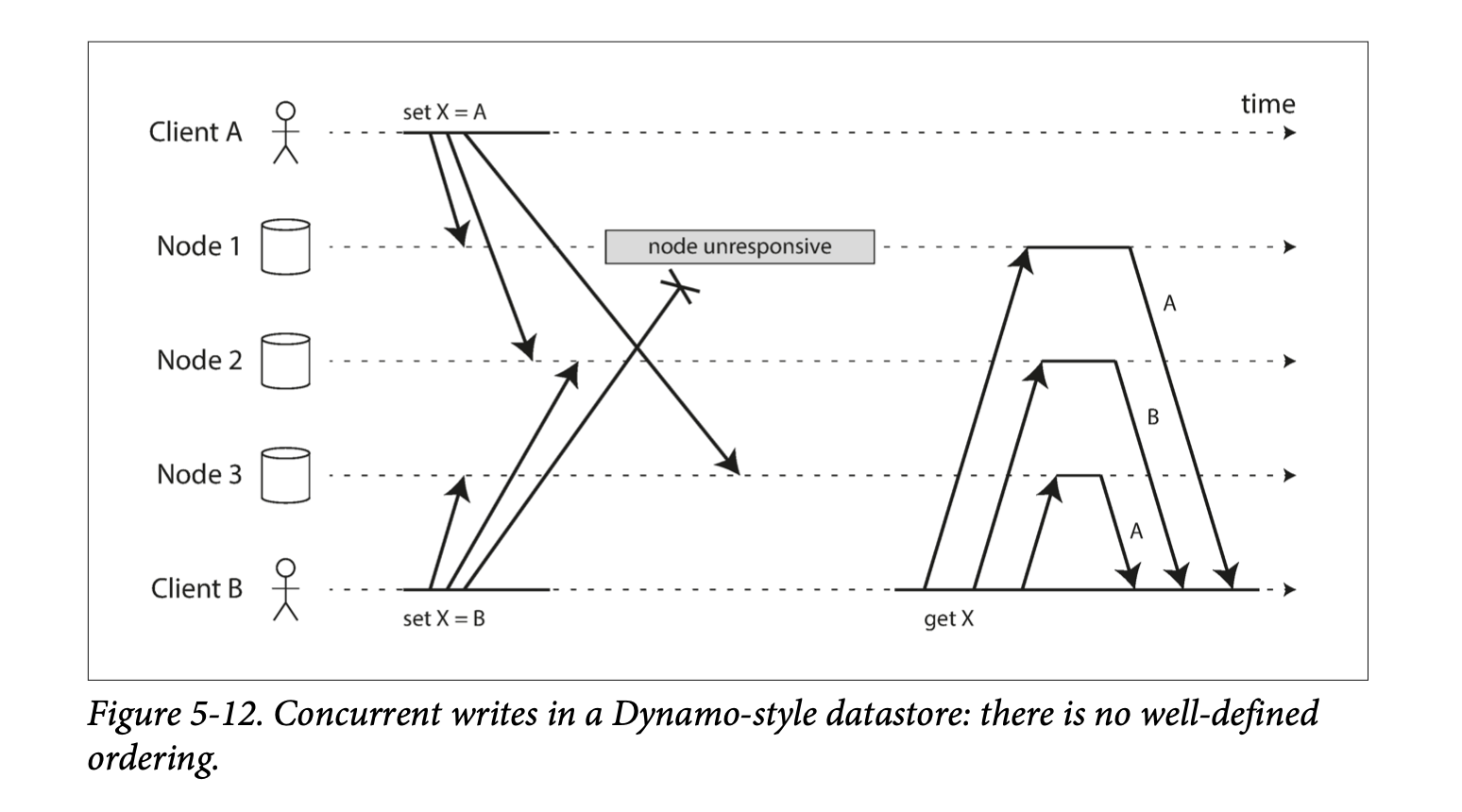
Nếu mỗi node chỉ đơn giản overwrite (ghi đè) giá trị cho key bất cứ khi nào nhận được yêu cầu từ write request, thì sẽ tạo ra inconsistent vĩnh viễn. Ví dụ 5-12, node 2 nghĩ rằng final value của X là B, trong khi các node khác nghĩa là A.
Để đạt được eventually consistent, các replica phải “hội tụ” về cùng giá trị. Chúng làm bằng cách nào? Ta có thể hy vọng database làm nó 1 cách tự động, nhưng ko may thay, hầu hết các implementation đều không tốt.
Last write wins (discarding concurrent writes)
Phương pháp này cho phép mỗi replica chỉ lưu the most “recent” value, và cho phép “older” value bị overwrite. Tuy nhiên, “recent” trong ngữ cảnh này thì mập mờ và dễ nhầm lẫn. Trong ví dụ 5-12, ta không thể xác định thứ tự write của request, không rõ request nào sẽ đến trước. Khi nói “concurrent request”, nghĩa là thứ tự ko được xác định
Ngay ra khi write không có natural order, ta có áp đặt 1 thứ tự bất kỳ cho nó. Ví dụ, thêm timestamp, timestamp nào lớn nhất là “recent” request và loại bỏ toàn bộ dữ liệu cũ.
The “happens-before” relationship and concurrency
Cần duy quyền mối quan hệ giữa các request. Giả sử request A xảy ra trước request B. Ta có thể nói A happens before B hoặc B is causally dependent vào A.
Khi có 2 operation A và B, có 3 trường hợp xảy ra: A xảy ra trước B, B xảy ra trước A hoặc A và B xảy ra đồng thời
Ngoài ra còn có một số phần mà tôi vẫn chưa hiểu, không đề cập ở phần này. Các sub-section gồm:
- Capture the happens happen-before relationship
- Merging concurrently written values
- Version vectors
Referenes: