67. [System Design] 07. Replication: phương pháp Master-master
Multileader hay master-master 1 phương pháp thiết lập replication. Tương tự với master-slave, nhưng multimaster cho phép ghi dữ liệu trên nhiều node khác nhau. Sau đó, sẽ thực hiện xử lý conflict khi có concurrent write.
Note: phương pháp này thường không được sử dụng rộng rãi và nên tránh khi có thể.
Use case for Multi-leader replication
Thông thường, multi-leader không được dùng nếu chỉ giới hạn trong 1 datacenter, vì lợi ích đạt được nhỏ hơn rất nhiều so với mức độ phức tạp được thêm vào. Tuy nhiên, có 1 vài trường hợp, ta có thể xem xét dùng multi-leader replication
Multi-datacenter operation
Giả sử bạn có nhiều datacenter và muốn replicate data tới nhiều datacenter khác nhau (có lẽ có thể chịu đựng việc toàn bộ 1 datacenter bị fail). Với single master-slave replication, master sẽ chỉ ở trong 1 datacenter.
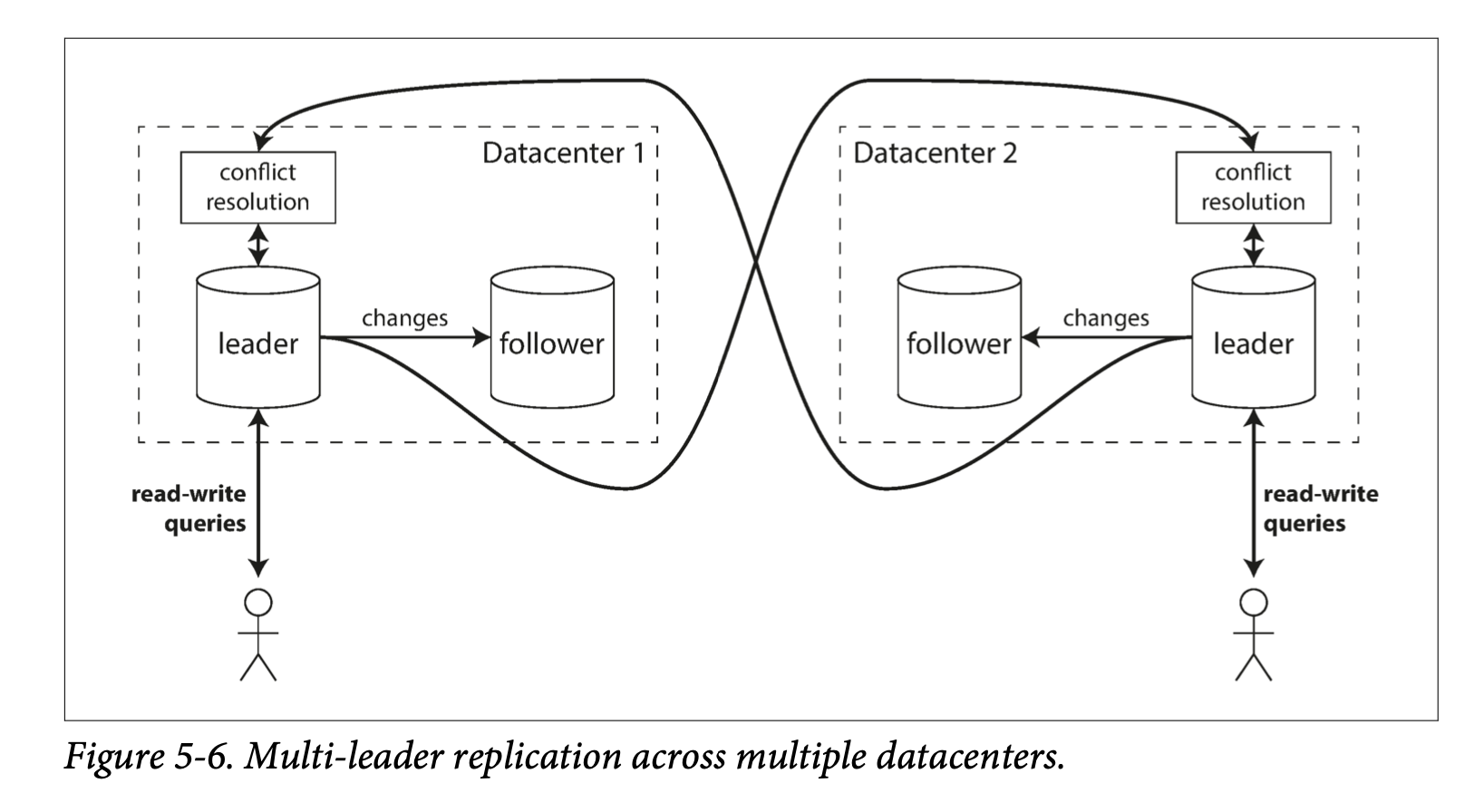
So sánh giữa single-leader và multi-leader config:
- Performance: Với single leader config, mỗi write request đều phải đi đến datacenter chứa leader, và điều này làm gia tăng đáng kể latency. Với multi-leader config, write request có thể xử lý ở local datacenter và sau đó được replicate asynchornously tới những data center khác. Việc xử lý giữa các datacenter thì bị “ẩn” với người dùng, nên hiệu suất tốt hơn
- Tolerence of datacenter outages:
- Tolerance of network problems:
Tuy nhiên, multi-leader cũng có 1 hạn chế rất lớn: nếu dữ liệu được thay đổi cùng lúc ở 2 datacenter khác nhau, conflict sẽ xảy ra và ta phải xử lý conflict này.
Ngoài ra, những thứ như auto-increament key, triggers, stored proceudure cũng có thể xảy ra vấn đề. Vì vậy, multi-leader replication thường không được sử dụng và nên tránh khi có thể.
Clients with offline operation
Đây là 1 dạng ứng dụng có thể tiếp tục hoạt động offline trong khi không kết nối với internet. Ví dụ calendar app, google docs, … Nếu có những thay đổi nào diễn ra offline, chúng cần được sync với server và những thiết bị khác khi chúng online
Trong trường hợp này, mỗi một thiết bị là 1 local database và hoạt động như một leader (chúng nhận write requests) và sẽ có quá trình sync dữ liệu giữa các device. Quá trình sync này (hay còn gọi là multi-leader replication process) có thể là async. The replication lag có thể là hàng giờ hoặc vài ngày, phụ thuộc vào việc khi nào thiết bị online
Từ góc nhìn của kiến trúc hệ thống, thiết lập như này giống với multi-leader replication giữa các datacenter, mà mỗi device là 1 datacenter. Với lịch sử phong phú của việc thất bại trong lúc sync calendar, nó chứng mình rằng multi-leader replication rất khó để hiện thực cách đúng đắn.
Collaborative editing
Real-time collaborative editing application cho phép nhiều người edit 1 document đồng thời. Ví dụ Google Docs.
Tác giả không nghĩ rằng collaborative editing là database replication problem, nhưng có nhiều điểm chung với trường hợp offline editing. Khi 1 user edit 1 document, sự thay đổi ngay lập tức được áp dụng tới local replica (trạng thái của document được lưu tạm thời trên web browser hoặc client application) và async replicated tới server hoặc những user khác đang edit cùng document
Nếu muốn đảm bảo không có editing confliect, ứng dụng cần duy trì lock với document trước khi 1 user có thể edit. Nếu 1 user khác muốn edit, trước tiên, họ cần phải đợi user đang giữ lock, commit những thay đổi và release lock. Mô hình này giống với single-leader replication with transaction trên leader
Tuy nhiên, để faster collaboration, bạn cần những thay đổi phải nhỏ (ví dụ: a single keystroke) và tránh locking. Phương pháp này cho phép nhiều user edit đồng thời, nhưng cũng mang đến những vấn đề của multi-leader replication, bao gồm việc xử lý conflict.
Handling Write Conflicts
Giả sử, User 1 thay đổi title từ A sang B. User thay đổi title từ A sang C cùng thời điểm. Mỗi thay đổi đều thành công trên local leader. Tuy nhiên, khi sự thay đổi async replicated, conflict xảy ra. Xem hình dưới
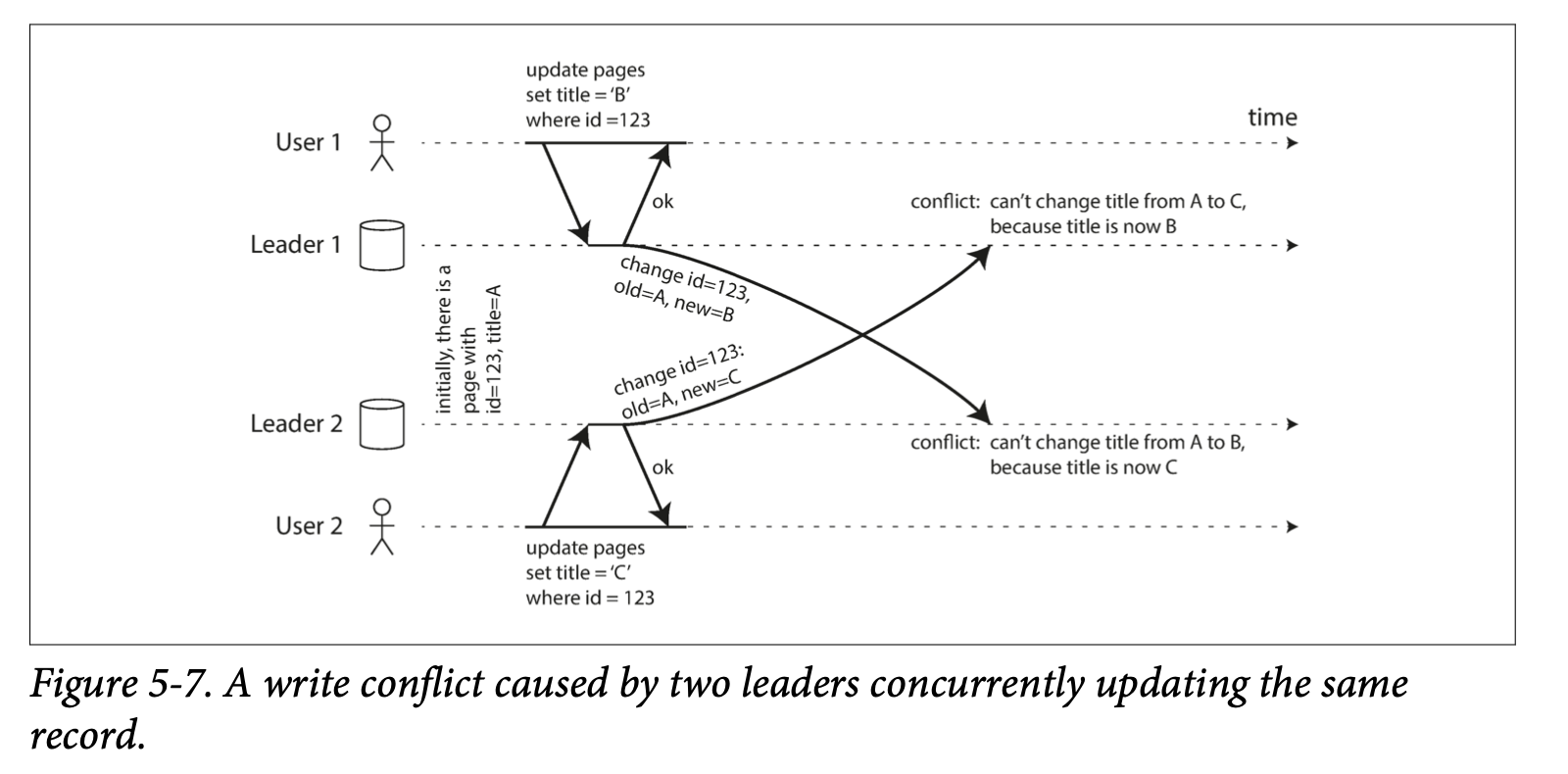
Synchronous vs Asynchronous confliect detection
Với single leader database, với write request thứ 2, hoặc là sẽ block và đợt write request thứ 1 xong, hoặc là sẽ abort (bỏ) write request 2 và force user gọi lại request 2. Với multi leader, vì write đã thành công trên leader, nên conflict chỉ được phát hiện sau đó, khi async replicated xảy ra. Và có lẽ đã qúa trễ để user xử lý conflict
Theo lý thuyết, với multi-leader, ta có thể đợi dữ liệu replicated tới toàn bộ node trước khi xác nhận write request thành công. Tuy nhiên, điều này làm mất đi lợi thế của multi-leader replication.
Converging toward a consistent state
Với single-leader database, write request có sequential order. Nếu có nhiều update tới cùng 1 field, update cuối dùng sẽ xác định giá trị của field đó. Tôi nghĩ, thật ra vấn sẽ có concurrent write request tới leader, nhưng leader database sẽ tự xử lý việc này, nên chúng ta không cần quan tâm tới vấn đề này.
Với multi-leader mode, không có bất kỳ thứ tự gì cho việc write, do đó, ta không biết chính xác final value là gì. Trở lại ví dụ về write conflict, ta không biết sau cùng giá trị của title sẽ là B hay C ? Ta cần phải đảm bảo giá trị của từng replica là giống nhau, hay hội tụ là 1 giá trị (convergent). Có nhiều cách để thực hiện như:
- Với mỗi write request, assign 1 unique ID (ex: a timestamp, long random number hoặc UUID,…), chọn write request mà ID là lớn nhất và đó là winner. Nếu timestamp được sử dụng, kỹ thuật này gọi là last write wins (LWW). Mặc dù kỹ thuật này phổ biến, nhưng cũng nguy hiểm vì dễ bị mất dữ liệu.
- Với mỗi replica, assign 1 unique ID (ở trên là assign ID cho write request, còn ở đây là assing ID cho mỗi replica), và luôn chọn replica có ID lớn hơn. Phương pháp này cũng gây ra data loss
- Merge value với nhau. Ví dụ sort theo alphabet và concat value. Với ví dụ ở trên, giá trị sau khi merge B và C là B/C
- Ghi nhận conflict và giữ lại toàn bộ data. Sau đó để application xử lý conflict ở 1 thời điểm nào đó.
Những cách này quá chung chung, có thể xem như keyword để tìm hiểu thêm.
Custom conflict resolution logic
Conflict resolution có thể được xử lý ở applicaiton logic. Code có thể thực thi ở write hoặc read.
- On write: Ngay khi database phát hiện conflict ở log of replicated changes, nó gọi là conflict handler.
- On read: Khi một conflict được phát hiện, tất cả các conflict đều được ghi vào database. Lần tới, khi data được đọc, sẽ có nhiều version của data được trả về. Ứng dụng có thể tự động xử lý hoặc cho phép user xử lý conflict, và sau đó ghi ngược lại vào database. CouchDB sử dụng phương pháp này
Conflict resolution thường áp dụng ở mức individual row hoặc document, không phải toàn bộ transaction. Nếu 1 transaction có nhiều lệnh write, mỗi lệnh write sẽ được xem xử lý conflict riêng biệt.
Lưu ý rằng việc xử lý conflict sẽ nhanh chóng trở nên phức tạp và dễ dàng xảy ra lỗi.
Referenes: