65. [System Design] 05. Replication: phương pháp Master - Slave. Phần 1
Introduction
Replication (nhân bản, nhân rộng) là một kỹ thuật giữ 2 hoặc nhiều bản sao của dữ liệu trên nhiều máy khác nhau. Mỗi bản sao được gọi là replica.
Vậy tại sao ta phải dùng kỹ thuật replication? Có một số nguyên nhân sau:
- Reduce latency: Giữ data gần với user hơn về mặt địa lý. Ví dụ user ở VN sẽ gọi tới data center ở Singapore và user ở UK sẽ gọi tới data center ở UK.
- Increase availability: Nếu 1 node trong system bị fail, hệ thống vẫn hoạt động bình thường
- Increase read throughput (scaling): khi lượng read tăng lên đến ngưỡng 1 server không chịu nổi, cần điều hướng lượng request đó sang nhiều server khác nhau. Có thể xử lý nhiều read queries hơn
Trong chương 5 này, chúng ta giả sử kích thước data đủ nhỏ để chứa trong 1 server duy nhất, không xét đến trường hợp data quá lớn, không thể chứa trong một máy.
Chương này sẽ đề cập đến ba phương pháp replication thông dụng, gồm master-slave, multi-master và masterless. Bài này sẽ tập trung vào giải thuật đầu tiên, master-slave
Phương pháp Master - Slave
Khi có nhiều replica, một câu hỏi lớn: Làm sao đảm bảo rằng dữ liệu được sync giữa các replica và master node ?
Master, còn được gọi là leader, primary, active node. Slave còn được gọi là follower, secondary và passive node. Master - slave model có nghĩ là chỉ có 1 master và nhiều slave.
Với phương pháp master-slave, ta có thiết lập sau:
- Có duy nhất 1 replica được chỉ định làm master. Khi client cần ghi dữ liệu vào database, chúng phải gửi write request vào master node, và master sẽ ghi dữ liệu vào local storage.
- Những replica khác được gọi là slave, và có nhiều slaves. Khi user gửi write request và master node đã ghi xong vào local storage, master node sẽ gửi những thay đổi này tới slaves node dưới dạng replication log hoặc change stream. Mỗi slave node sẽ update local storage của nó theo đúng trình tự được sử lý trên master node.
- Khi client cần read query, nó có thể đọc từ master hoặc slaves. Cần nhớ rằng, chỉ write vào master node và slave node là read-only.
Bên dưới là mô tả về phương pháp master-slave từ trong sách [1].
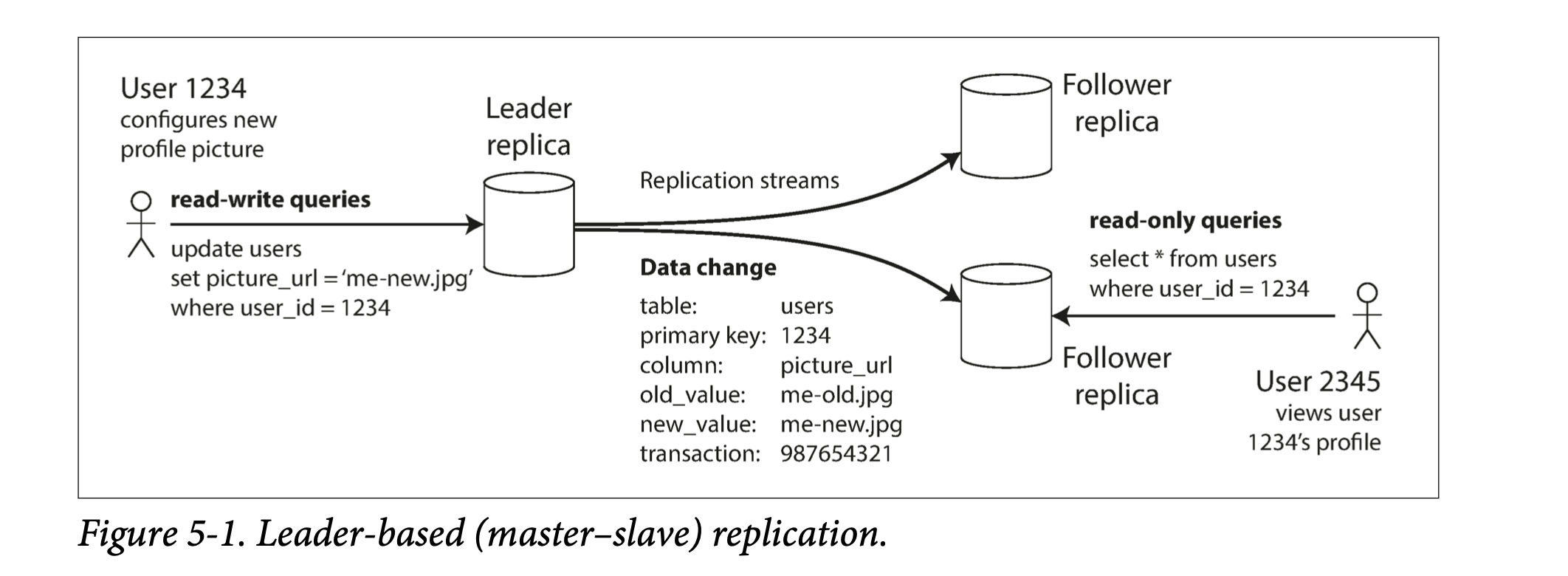
Phương pháp này là built-in feature của nhiều relational database như Postgres (từ version 9.0), Mysql, … Và một số non-relational database như MongoDB. Hơn thế nữa, Master-Slave approach không chỉ giới hạn trong database, mà còn có thể sử dụng ở distributed message broker như Apache Kafka và RabbitMQ
Synchronous Versus Asynchronous Replication
Một vấn đề cần quan tâm là replication được thực hiện theo cơ chế synchronous hay asynchronous
Synchronous replicaiton: đảm bảo rằng tất cả replica nhận được và thực hiện thành công write request, rồi mới gửi thông báo thực hiện thành công về cho client. Sync đảm bảo rằng tất cả các node đều có dữ liệu mới nhất (up-to-date data). Điểm bất lợi là nó yêu cầu tất cả các slaves node phải phản hồi và làm tăng response time. Nếu có 1 node không phản hồi, thì write request không thể thực hiện được, dẫn tới system bị đưa vào trạng thái tạm dừng. Trong thực tế, ngoài master node, sẽ dùng sync trên 1 slave node bất kỳ, những slave node còn lại sẽ là async. Phải bảo đảo ít nhất dữ liệu lưu ở 2 nơi trước khi phản hồi với người dùng rằng write request đã thành công. Trường hợp nếu slave node được chọn không hoạt động hoặc phản hồi chậm, một slave node khác được chọn. Configuration này được gọi là semi-synchronous.
Asynchronous: Master node sẽ gửi message/lệnh tới slaves node nhưng không đợi phản hồi từ slaves. Thường thường, master-slave replication sẽ được config completely asynchronous. Trong trường hợp này, nếu master node fail và không thể recover, những write request chưa được replicated sẽ bị mất. Nghĩ là completely async không đảm bảo durable (D trong ACID). Tuy nhiên, nếu slave node fail hoặc network xảy ra vấn đề, ta vẫn có thể write bình thường, nhưng lại ko đảm bảo consistency. Có 1 liên kết mạnh mẽ giữa replication consistency và consensus (the number of node that agreed on a value), sẽ tìm hiểu ở chapter 9.
Quá trình replication thường diễn ra nhanh (nhỏ hơn 1s). Tuy nhiên, không có gì chắc chắn về thời gian cần thực hiện replication. Trong vài trường hợp, có thể tốn 1 phút tới vài giờ. Các nguyên nhân có thể có là do server restart, network problems, …
Setting Up New Followers (Slaves)
Khi thêm mới 1 slave, không chỉ đơn giản là copy data từ node này sang node khác, vì client luôn luôn ghi dữ liệu vào database, dữ liệu luôn thay đổi, không có trạng thái cố định.
Để đơn giản, bạn có thể block toàn bộ write data trong quá trình copy hoặc shutdown system, nhưng điều này chống lại mục tiêu high availability.
Để quá trình thêm 1 node mới không xảy ra downtime, có thể tham khảo các bước sau:
- Take a snapshot của master database tại 1 thời điểm nào đó, tốt nhất là không cần lock toàn bộ database trong quá trình này. Hầu hết database đều có tính năng này
- Copy snapshot tới node mới
- Node mới kết nối với leader và yêu cầu toàn bộ data change đã xảy ra từ lúc tạo snapshot. Điều này yêu cầu snapshot biết vị trí của snapshot trong master’s replication log. Với Postgres, nó được gọi là log sequene number, với Mysql là binlog coordinates
- Khi slave node xử lý xong toàn bộ backlog khi data change từ lúc snapshot, ta gọi quá trình này là catch-up. Lúc này, slave node có thể hoạt động bình thường. Quá trình thêm 1 node mới kết thúc.
Handling Node Outages
Mục tiêu: có thể handle nếu master hoặc slave node xảy ra downtime. Điều này rất có lợi cho việc vận hành, khi phải reboot để update phần mềm, node fail, network issue
Slave failure (catch-up recovery): dựa vào log trên mỗi slave node, nó có thể biết transaction cuối cùng được thực thi trước khi fault xảy ra. Sau đó, liên hệ với master node để apply những thay đổi từ last transaction đó.
Leader failure (Failover): Failover thì tricker hơn catch-up recover. Failover có thể xảy ra manual hoặc tự động. Automatic failover gồm những bước sau:
- Xác định rằng master đã fail. Thường sử dụng heartbeat và timeout
- Chọn một node làm master: có thể thông qua election process hoặc được chỉ định. (Chưa hiểu rõ vụ này, sẽ nói rõ hơn ở Chap 9). Ứng cử viên tốt nhất thường là replica có up-to-date data change, để tối thiếu hoá đata loss.
- Reconfig để hệ thống dùng node master mới. Lúc này, client sẽ send request tới node master mới. Nếu old master trở lại, hệ thống phải đảm bảo old master thành slave.
Quá trình failover có nhiều điểm có thể gây ra lỗi:
- Nếu async replication được sử dụng, new master có thể không có up-to-date data từ old master. Nếu old master rejoin, write conflict có thể xảy ra. Phương pháp thông dụng nhất là loại bỏ toàn bộ unreplicated data củao old master
- Tuy nhiên, việc loại bỏ data này là nguy hiểm nếu những storage system khác ngoài database dựa vào dữ liệu của database. Ví dụ tại Github, out-of-date MySQL slave được đề cử làm leader. Database này sử dụng auto-incrementing counter để gán primary key. Nhưng vì new master counter bị chậm (lag) so với old master, nên nó tái sử dụng một số primary key đã được assign bởi old master. Và những primary key này cũng được dùng cho Redis. Điều này gây ra một vài private data bị tiết lộ sai user. Ví dụ với old master, couter 55 được gán cho user A. Redis cũng dùng counter 55 cho user A. Và lúc này old master bị crash, và chưa kịp replicate thông tin này tới new master. Lần tới, new master tạo counter mới cho user B, và giá trị là 55. Tuy nhiên, khi lấy giá trị từ Redis, user B có thể đọc private info của của A.
- Xử lý khi new và old master cùng tồn tại khi old master sống lại. Phải xử lý cẩn thận, tránh tình trạng cả 2 node này đều bị shutdown
- Khi xác định node đã chết, timeout thích hợp là bao nhiêu? Longer timeout nghĩa là thời gian phụ hồi sẽ dài hơn. Nhưng nếu timeout quá ngắn, việc thực thi failover là không cần thiết.
Giải pháp cho những vấn đề trên không dễ. Vì vậy, một số operation team ưu tiên thực hiện failover thủ công, kể cả nếu phần mềm có hỗ trợ failover tự động.
Referenes: